
🍔🧠 How DoorDash Uses LLMs To Predict 10M+ Customer Grocery Lists
PLUS: Google Stack Breakdown 🛠️, S3's Trillion-File System 💾, Compression Algorithms ⚡

Today’s issue of Hungry Minds is brought to you by:

Happy Monday! ☀️
Welcome to the 224 new hungry minds who have joined us since last Monday!
If you aren’t subscribed yet, join smart, curious, and hungry folks by subscribing here.

📚 Software Engineering Articles
The last AI agent builder you’ll ever need
How Grab saved 70% costs by switching from Go to Rust
AWS S3’s secret to serving petabytes using slow HDDs
Smart username lookup architecture behind availability checks
Inside Google’s tech stack: engineering culture revealed
Debug like a pro with these game-changing techniques
🗞️ Tech and AI Trends
Top researchers form AI dream team, leaving tech giants behind
OpenAI’s Sora becomes App Store sensation
Meta’s ambitious plan to power humanoid robots
👨🏻💻 Coding Tip
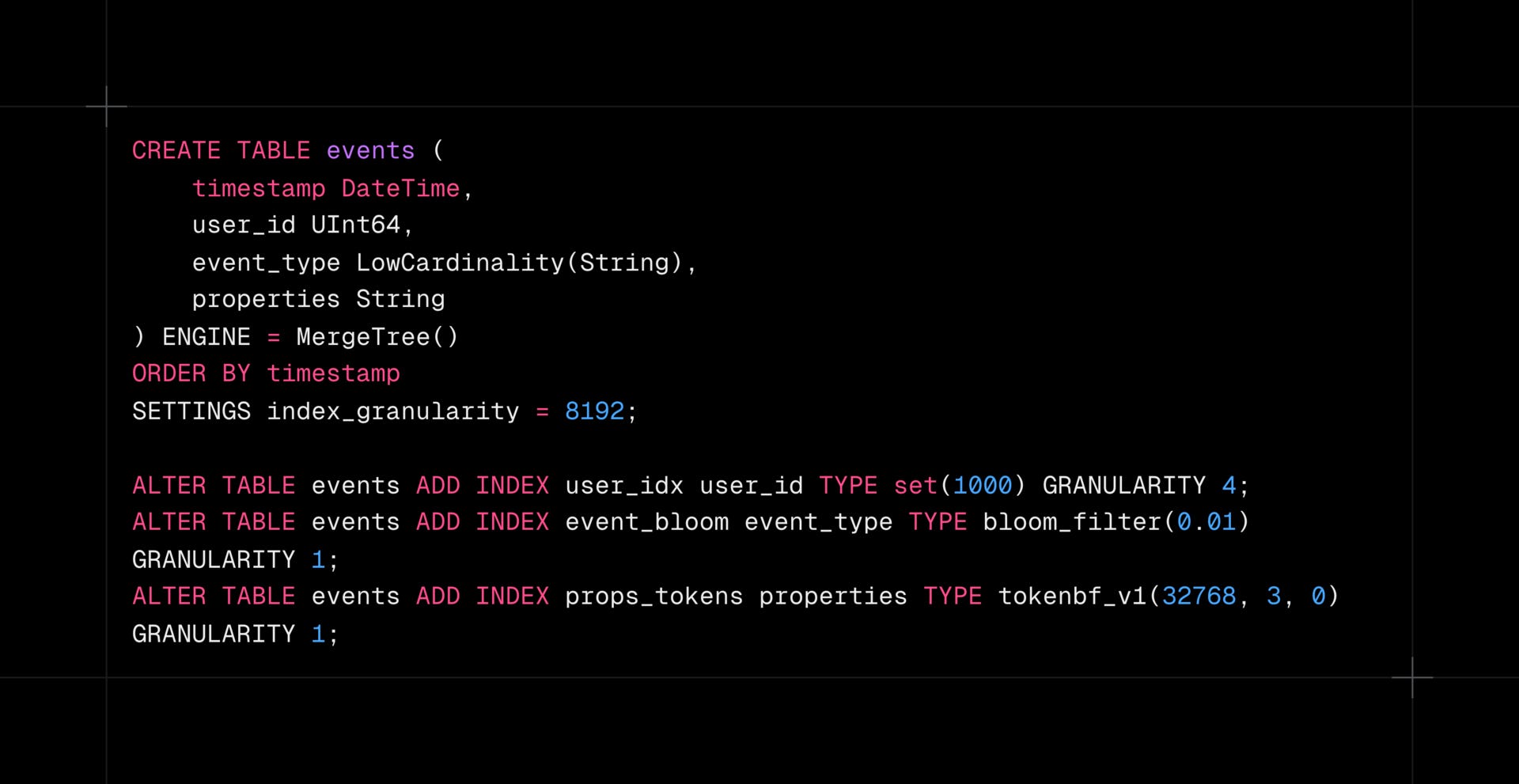
Query patterns and indexing smartly
Time-to-digest: 5 minutes
A simpler way to build reliable agents, powered by APIs you can trust 🤖

✅ No custom code
Visually built the entire workflow logic. No more fragile scripts to maintain.
✅ Pre-built trusted APIs
Connected instantly to PagerDuty, Datadog, and Slack from Postman’s huge API library.
✅ Modular and adjustable
When a schema changes, update 1 node in the flow in minutes. No code deployment needed.

How DoorDash uses LLMs to predict grocery preferences from restaurant orders 🥘
DoorDash transformed how they solve the cold-start problem for grocery recommendations by leveraging restaurant order history. Instead of recommending random items to new grocery customers, they built an LLM-powered system that analyzes what you order from restaurants to predict what you’ll want from their grocery stores.
The challenge: Scale LLM inference to 200+ million users without burning through seven-figure costs per run while maintaining recommendation quality.
Implementation highlights:
Tag-based compression: Replace raw order data with structured dish/cuisine/dietary tags to dramatically reduce LLM context size
Offline tagset mapping: Pre-compute mappings from unique tag combinations to grocery taxonomies weekly instead of running individual LLM calls per user
RAG-powered retrieval: Use K-NN search to narrow 1000s of grocery categories down to ~200 relevant candidates before LLM inference
Hybrid scoring model: Combine recency and frequency signals with LLM relevance scores to personalize recommendations for each user
LLM-as-judge evaluation: Implement automated quality assessment using LLM judges with metrics like nDCG@3 and quadratic weighted kappa
Results and learnings:
Massive cost savings: Achieved ~10,000x cost reduction compared to naive per-user LLM approach
Statistical significance: Observed measurable improvements in order penetration for both convenience and grocery verticals
Quality at scale: Successfully maintained recommendation relevance while serving 200+ million active users
DoorDash proves that smart architecture beats brute force when scaling LLMs. Their approach shows how proper data compression and offline pre-computation can make expensive AI affordable while maintaining quality.
Who knew that your obsession with Korean BBQ could help you discover the perfect kimchi selection? Your delivery history has been judging your grocery game all along!

Postman AI Agent Builder
Build AI agents faster with Postman AI Agent Builder. Access verified APIs, the latest LLMs, and tools for seamless workflows.
API Versioning - A Deep Dive
Written by

The secret architecture behind “username already taken”
Written by

Taking a Look at Compression Algorithms

Dissecting various compression algorithms.
Vibe Coding Is The Only Future
Written by

Inside Google’s Engineering Culture: the Tech Stack (Part 2)
Written by

My Most Important Learning in Software Engineering
Written by

Companies Should Stop Obsessing Over AI Tools And Do This Instead
Written by

ESSENTIAL (code getting cheaper)
Programming deflation
ARTICLE (jack-of-all-trades-master-of-fun)
Generalists in 2025
ARTICLE (paper-eating-robots)
Advanced Document Processing using AI
ESSENTIAL (rust-saves-money)
How Grab’s Migration from Go to Rust Cut Costs by 70%
ARTICLE (hiring-oopsie)
The Startup Hiring Lie Nobody Talks About
ESSENTIAL (hard-drives-go-zoom)
How AWS S3 serves over petabyte per second with slow HDDs
ARTICLE (fuzzy-address-finder)
Address matching using a fault tolerant trie
ESSENTIAL (bug-squashing-101)
Debug like a PRO
Want to reach 190,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

🛍️ OpenAI Challenges E-commerce Giants with ChatGPT In-Chat Shopping (4 min)
Brief: OpenAI launches Instant Checkout feature allowing direct purchases through ChatGPT from Etsy and soon Shopify merchants, while open-sourcing its Agentic Commerce Protocol to potentially reshape online shopping dynamics against Google and Amazon’s dominance.
📱 OpenAI’s Sora Becomes #1 App on US App Store Despite Invite-Only Status (3 min)
Brief: OpenAI’s new AI video app Sora hits 164,000 installs in two days and reaches #1 on the US App Store, surpassing ChatGPT and Google Gemini despite being invite-only and limited to US and Canada.
🤖 Apple Launches Foundation Models Framework for Intelligent iOS Apps (5 min)
Brief: Apple releases its Foundation Models framework with iOS 26, enabling developers to create on-device AI features in apps across health, education and productivity, with free AI inference and offline privacy protection.
🤖 Anthropic’s Claude Sonnet 4.5 Sets New Record with 30-Hour Autonomous Coding Session (4 min)
Brief: Anthropic launches Claude Sonnet 4.5, an AI model capable of 30-hour autonomous operations and advanced coding capabilities, representing a significant leap from their previous 7-hour record and positioning itself as a leader in AI agents and computer use.
🤖 Meta Aims to Power the Future of Humanoid Robots Through Software (3 min)
Brief: Meta’s CTO reveals plans to become the software backbone for humanoid robots through a major investment comparable to their AR projects, focusing on solving complex challenges like object manipulation rather than hardware manufacturing.

This week’s coding challenge:
This week’s tip:
ClickHouse skip indexes dramatically improve query performance on large tables by eliminating data blocks before reading. Combine minmax, set, and bloom_filter indexes strategically based on query patterns.
Wen?
Time-series analytics: Skip entire date ranges when filtering by user cohorts or event types
Log aggregation systems: Rapidly filter multi-TB tables by specific error codes or trace IDs
E-commerce analytics: Efficiently query product interactions across millions of user sessions
As you grow older you will discover that you have two hands. One for helping yourself, the other for helping others.
Audrey Hepburn

That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).
The offline pre-computation strategy is genius - transforming an expensive per-user LLM problem into a weekly batch job is exactly the kind of engineering pragmatism that scales. What really impresses me is the hybrid scoring model combining recency/frequency with LLM relevance scores. Too many teams treat LLMs as a hammer for every nail, but DoorDash recognized that classical signals still matter for personaliztion. The 10,000x cost reduction is staggering and proves that clever architecture beats brute force. I'm curious about the edge cases though - what happens when someone's restaurant orders are gifts or for others? The RAG approach with K-NN narrowing the search space before LLM inference is particularly smart for keeping latency down while maintaining quality. Great breakdown!