
🍔🧠 Build Your Own 280M-Page Search Engine (Complete Blueprint Inside)
PLUS: How Webhooks Work ⚙️, Rust Replaces Elasticsearch & MongoDB 🦀, AI Startup Bids $34.5B for Chrome 🚀

Happy Monday! ☀️
Welcome to the 271 new hungry minds who have joined us since last Monday!
If you aren’t subscribed yet, join smart, curious, and hungry folks by subscribing below.

📚 Software Engineering Articles
Learn how to build resilient services with failure handling strategies
This company replaced Elasticsearch with Rust and RocksDB for better performance
Master the differences between API Gateway and Load Balancer
Webhooks explained with real-world architecture examples
Optimize costs by avoiding repeated LLM calls
🗞️ Tech and AI Trends
Claude's 1M token update revolutionizes long-context AI processing
Perplexity's shocking $34.5B bid for Chrome browser
Streaming costs push viewers back to piracy
👨🏻💻 Coding Tip
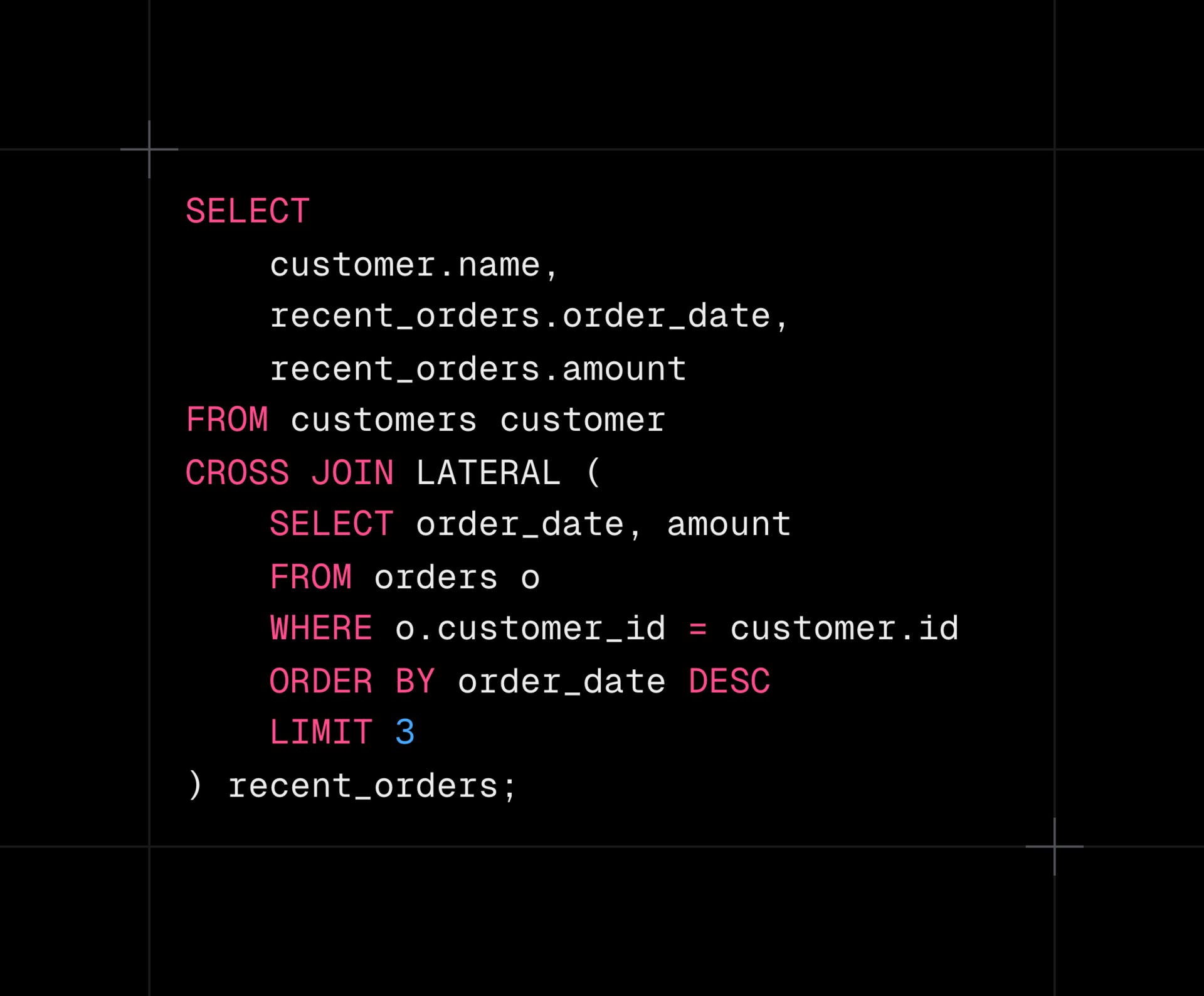
Postgres LATERAL JOIN optimizes complex queries for top-N group operations
🔥 55% off on the best system design courses; ends today!
I’ve partnered with the best e-learning company to help you learn system design.
You will find:
900+ hands-on courses
310+ real-world projects
Mock interviews and personalized paths
All of that bundled with hands-on learning and AI!
The 55% off offer ends in roughly a day; grab it while it lasts! 🔥

Building a Search Engine From Scratch with 3B Neural Embeddings in 2 Months 🧱
A solo developer built a neural search engine from scratch that processes 3 billion embeddings and delivers results in 500ms. This project showcases how modern AI techniques can create a more intelligent search experience while maintaining high performance at scale.
The challenge: Build a production-grade search engine that understands query intent (not just keywords) while handling billions of embeddings with limited resources and budget.
Implementation highlights:
Neural-first architecture: Used SBERT embeddings to enable natural language understanding and semantic search capabilities
Distributed processing: Built a cluster of 200 GPUs, generating 100K embeddings/second with 90% GPU utilization
Custom infrastructure: Created sharded HNSW indices and RocksDB stores across 200 cores and 82TB of SSDs
Cost optimization: Leveraged lesser-known providers like Runpod and Hetzner to achieve 40x cost savings vs. AWS
Streaming design: Implemented HTTP/2 multiplexing and server-side rendering for sub-500ms query latency
Results and learnings:
Quality results: Successfully filtered SEO spam and surfaced high-quality content through semantic understanding
Massive scale: Processed 280M pages and generated 3B embeddings while maintaining sub-second latency
Cost effective: Entire system could be sustained by ~10K $5/month subscriptions
Neural search engines can deliver significantly better results than keyword matching while remaining highly performant. This project proves that even massive-scale search systems can be built by small teams with the right architecture choices.

API Gateway vs Load Balancer

How Do Webhooks Work ⭐
Written by

Meta Senior Manager (M2) on Manager Career Growth, PIPs, Amazon vs Meta
Recorded by

Every repeated LLM call is money on fire
Written by

The reality of AI-Assisted software engineering productivity
Written by

ARTICLE (mission-possible)
How to Define your Team's Mission
ARTICLE (ai-vs-vibes)
Prompt Engineering vs Spec Engineering. Coding with AI like a Senior Engineer in Big Tech
ESSENTIAL (typescript-or-bust)
Why You Can't Afford to Ignore TypeScript
ARTICLE (star-wars-fix)
Your STAR Method Is Broken
ARTICLE (spin-to-win)
The Art of the Personal Fly-Wheel
ARTICLE (graceful-crash)
How to Keep Services Running During Failures?
ARTICLE (rust-go-brrr)
How we replaced Elasticsearch and MongoDB with Rust and RocksDB
ESSENTIAL (trifecta-vibes)
Rust, Python, and TypeScript: the new trifecta
ARTICLE (css-oopsh)
We Keep Reinventing CSS, but Styling Was Never the Problem
ARTICLE (postcss-wisdom)
What we learned from creating PostCSS
Want to reach 190,000+ engineers?
Let’s work together! Whether it’s your product, service, or event, we’d love to help you connect with this awesome community.

🤖 How Claude Code Became My AI-Powered Productivity Swiss Army Knife (8 min)
Brief: A developer chronicles their transition to Claude Code as their primary tool, replacing GPT for coding, automating startups, migrating production apps, and even editing text, despite occasional hallucinations and policy restrictions.
🚨 Wikipedia Loses Legal Fight Against UK's Online Safety Act Verification Rules (3 min)
Brief: Wikipedia's challenge to the UK's Online Safety Act fails, potentially forcing the platform to verify editors' identities—a move it claims threatens user privacy and volunteer safety.
🎬 Streaming Piracy Surges as Services Hike Prices and Cut Content (2 min)
Brief: Rising subscription costs and shrinking libraries are pushing frustrated viewers back to piracy, as major streaming platforms struggle to retain customers amid financial pressures.
🤖 Claude Code: The AI Tool That Replaced My Dev Stack (6 min)
Brief: A developer details how Claude Code replaced his GPT subscription, text editor, and dev tools, enabling rapid creation of CRUD apps, autonomous startups, and even bank admin scripts with minimal human oversight.
🤖 AI Startup Perplexity Aims to Dethrone Google Chrome with $345B Bid (2 min)
Brief: AI challenger Perplexity makes unprecedented $345 billion offer to acquire Chrome's search dominance from Google by 2025, promising revolutionary AI-powered browsing.

This week’s coding challenge:
This week’s tip:
Use the Postgres LATERAL JOIN to execute correlated subqueries that reference previous FROM items and handle complex row-dependent calculations efficiently. This powerful feature enables dynamic subquery execution per outer row, ideal for top-N per group queries or dynamic filtering.
Wen?
Top-N per group queries: Fetch the most recent orders, highest-value transactions, or latest comments for each user/group.
Dynamic row-dependent calculations: Computing aggregates or summaries that depend on other table rows with complex filtering.
Denormalized data generation: Creating flattened views or materialized data structures where child records need intelligent selection based on parent attributes.
"I have been impressed with the urgency of doing. Knowing is not enough; we must apply. Being willing is not enough; we must do."
Leonardo da Vinci

That’s it for today! ☀️
Enjoyed this issue? Send it to your friends here to sign up, or share it on Twitter!
If you want to submit a section to the newsletter or tell us what you think about today’s issue, reply to this email or DM me on Twitter! 🐦
Thanks for spending part of your Monday morning with Hungry Minds.
See you in a week — Alex.
Icons by Icons8.
*I may earn a commission if you get a subscription through the links marked with “aff.” (at no extra cost to you).